+
(+ [number...]) ; => numberAdds the given numbers together, left to right, and returns the sum. If only one number is provided it is simply returned.
A hackable hobby programming language and toolset for having fun and making cool things
Slope is a dynamically typed ↗ programming language with lexical scope↗loosely situated in the LISP ↗ family of programming languages. It is an easy language to work with and has enough batteries included to get a beginner going for many programming tasks, even some basic gui programming. Plus: it is fun!
Slope's focus is on easing everyday terminal based tasks, with a dash of gui and a pinch of (very limited) concurrency. It features LISP style (unhygeinic) macros to enable metaprogramming. Files, network connections, and string buffers are all handled the same way: as readable or writable data containers; which simplifies dealing with each of them since they same set of procedures operate on all of them.
Slope is not intended to be the most powerful language in the world or to have the newest hot features. It is meant to be beginner friendly, fun to use, and be independenly developed by/with enthusiasts as a non-commercial programming language built for fun, not profit.
Pre-built binaries of the Slope interpreter are not currently available. As such, you will need to build from source. This isn't as scary as it sounds. You will need a few things on your system (two of which are likely already present):
Slope can be built for Linux, BSD, or Mac OSX. There is currently no windows support (get in touch if you'd like to help get it working for windows). All three of the above pre-requisites should be available in most package managers for Linux and BSD. Brew, for OSX, should also have all of them. In fact, Git and Make are likely already installed on your system!
To install Slope (once all of the above pre-requisites are met), open a terminal emulator run the following:
git clone https://tildegit.org/slope-lang/slope
cd slope
make
sudo make install
If you do not have administration privileges on your system omit the line sudo make install and you can just move the file slope to somewhere on your $PATH.
There are a few modules that can be built into the slope interpreter. They generally add graphical functionality. On linux/bsd they will require an X11 or Wayland environment to be useful. They should all function fine on OSX. dialog adds support for system dialogs, which enables a sort of light version of gui coding allow users to select files, pick colors/dates, respond to messages, etc. gui is a full native gui system. clipboard allows interaction with the system clipboard.
If you wish to install the optional modules you can run the following instead of the above installation instructions:
git clone https://tildegit.org/slope-lang/slope
cd slope
SLOPE_TAGS="all" make
sudo make installThe same caveat about administration privileges applies here as well. You will notice that we create a variable all that holds the names of the modules we want to build. The example uses all, but they can be added individually. The available modules are: dialog, gui, and clipboard. They can be combined like so:
SLOPE_TAGS="dialog clipboard".
You should be able to access the interpreter by typing slope at your shell prompt. If the executable that was built did not get moved to your path then you will need to access it directly by typing the path to it, which after building in the repository directoy is likely: ./slope. The full install (with admin privileges) will also install a man page for the interpreter, which can be accessed by entering man slope at your shell prompt.
There are a few different ways to interact with the Slope interpreter. In the following sections it will be assumed that the slope executable is on your $PATH and can be executed by typing slope at your shell prompt.
The repl is a great place to prototype ideas, get help, build up programs, or start modules. In general it is a great way to work with Slope code in real time.
To launch the repl type slope at your shell prompt. You should see something like the following (possibly with a different version number):
┌─┐┬ ┌─┐┌─┐┌─┐ └─┐│ │ │├─┘├┤ └─┘┴─┘└─┘┴ └─┘ Version: 1.2.2 (+gui) (c) 2021 sloum, see license with: (license) Type (exit) to quit > _
From here you can type in Slope code and see the results in real time. For example, you can type a number such as 156.23401 and the interpreter will return that number as a result since numbers evaluate to themselves (as does everything that is not a function or macro call).
The repl has a number of useful features that make it easier to work with. The most basic of which is the ability to edit the line of text you are on. You can use the Left Arrow and Right Arrow keys to move the cursor around the line. There are a number of key chords ↗ available to make editing easier. For example, Ctrl + a to move the cursor to the beginning of the line or Ctrl + k to delete from the cursor position to the end of the line.
The repl keeps a history file. As you are using the repl you can use Up Arrow and Down Arrow to bring up commands from your repl history.
If you start typing and press the Tab key you can cycle through any available completion options. For example, if you type (usa + Tab it will likely fill in the text to create (usage. If multiple completions are available subsequent presses of the Tab key will cycle through them. Shift + Tab will cycle through in reverse order. These completions work for any symbol in the standard library and any modules that expose usage information for their symbols (this will be covered in the section on module creation).
Slope features a procedure in the standard library named usage. It can provide information on any symbol in the standard library, as well as help for symbols exposed via module's _USAGE variable. More in depth information about using the built in help is covered in the section getting help.
User created namespaces are available via a number of procedures that work with them. If you do not know what namespaces are, dont worry! They can be an easy way to organize your code. There is even support for exporting a namespace as a string, which allows you to write it to a file for later use. This provides an easy mechanism to take the things you develop in a repl session and save them for later, or use them toward building a module. User namespaces will be covered in depth in the section user namespaces.
The main way people tend to distribute Slope software will be as files. By convention (ie. optionally) slope files use the file suffix .slo.
To run a file with the slope interpreter you can pass the file path as an argument to slope at your shell prompt:
slope ~/scripts/my-slope-file.sloThe Slope interpreter will also recognise a shebang ↗ line placed at the very top of the file. A common shebang for Slope might look like this:
#! /usr/bin/env slope
If you include a shebang and make the file executable (ie. via chmod ↗) you can directly execute the file:
./my-slope-program
The -run flag is supported by the interpreter to allow you to pass in a string and have it get interpreted. This is mostly useful for quick things, but it does still support module loading and any other features that the interpreter supports. Do note that it will behave as if the text was run from file and you will not see procedure results like you would in the repl. So if you want to see output you must call a procedure like write or display and have it print to stdout or stderr. For example:
slope -run "(display (+ 2 3))"
The above would output 5.
There are a number of ways to write a Hello, world! ↗ program in the Slope. We will cover the simplest case here (but we will cover it using all three of the ways we talked about above).
Open the Slope repl by typing slope at your shell prompt. Once you see the repl prompt type (display "Hello, world!") + Enter. You should see the string "Hello, world!" printed to the screen just below what you typed in.
Add the following to a file (for our example here we will call the file hello.slo and it will be in our current directory):
(display "Hello, world!")
Once you have saved the file, you can run it with the interpreter. For example, to run our imaginary example file that is in our current directory we would type (at our shell prompt): slope ./hello.slo + Enter. You should see the words "Hello, world!" printed to the screen just below where you invoked the interpreter and the file.
At your shell prompt type slope -run '(display "Hello, world!")' + Enter. Like in the above example, you should see "Hello, world!" printed just below the line you entered.
As mentioned above, Slope has a built in help procedure named usage. We have not covered calling procedures yet in this walkthrough, but explicit examples of how to use the usage procedure will be provided here.
usage can be called with or without an argument. When called without an argument it will print out all of the procedures it has usage information available for. This will include all of the standard library, as well as any modules that expose usage information and have already been loaded via the load-mod procedure (more on that later). So, this:
(usage)Will output something along the lines of this (truncated):
(usage [[procedure: symbol]]) => ()
Known Symbols
PHI PI
^ abs
and append
apply assoc
assoc? atan
atom? begin
begin0 bool?
; [...Results truncated...]
The first line shows how the usage procedure itself is called, via a procedure signature. It starts with an open parenthesis (like all procedure calls) followed by the keyword usage, followed by double square brackets (which denote an optional argument, single square brackets are a required argument) containing a title and a type. In the above case the title procedure and its type symbol This means that usage can be called without an argument or with one. The argument it is called with should be of the type keyword and it should represent a procedure's name. It then shows the symbol =>, which tells you that what comes after is what the procdure returns. In this case it returns an empty list (usage, as a side effect, prints the info you want to stdout and just returns the empty list since all procedures return something in Slope).
After the procedure signature a list of known procedure names is given. This can be useful if you do not remember exactly what procedure name you want, or if you just want to explore options.
Once you know what procedure you want, you can get the usage information for it. Lets try getting usage information for the bool? procedure:
(usage bool?)Which will print out something like the following (and return an empty list):
(bool? [any]) => bool
Checks whether the given argument is a bool: either the atom #t or the atom #f
You can see from the procedure signature that bool? requires a single argument (denoted by a single set of square brackets). That argument does not have a name (which is the case when there is not a name and type. The type is compulsory). The argument can be of any type. It will return a boolean value. The procedure description gives you more details about what it does. In this case it tells you if the argument you give it is of type bool or not.
As you can see, having help in this way available at your repl session can be quite useful and help you get used to a new system or just help you find what you are looking for.
Also remember that the repl has tab completion. So, for example, you could try to find a particular string procedure without knowing the exact name by typing (usage string + Tab. The first completion would result in something like (usage string->bytes a second press of tab might result in (usage string->list. And so on...
This website also serves as a great resource for general information as well as the same listing of procedures covered by usage (excluding loaded modules).
Slope syntax, like most scheme/lisp oriented languages, is very regular. Almost everything in slope outside of comments is a procedure call. Even things like math operators are procedure calls in Slope. As such doing addition takes the procedure name + then the values that are to be added. This is called polish notation ↗, and it might be conceptually helpful to read that link, as it is an adjustment to how people usually think. The benefits are that everything is called the same way and everything is regular.
Comments in Slope begin with a ; and go to the end of the line. Nothing from the ; to the end of the line will be executed. This is being mentioned here so that comments can be used in examples. This lets you comment out code easily by putting a ; at the beginning of the line or just adding some notes after some of your code to help remember what it does or add TODO items.
By convention multiple semicolons are used to give heirarchical structure to comments. But this is not required and there is no specific meaning to it, from an interpreter perspective. Generally speaking top level comments are denoted as ;;;, these are usually descriptions at the top fo a file. Full line comments describing individual areas of code, usually procedures, are denoted as ;;. Commenting out code is done with a single semicolon and comments that appear at the end of a line after code that will run are denoted as ;
;;; I am a top level comment
(+ 1 2) ; I am a comment that is complementary to code
; (+ 3 4)
;; The above line is commented out code. It will not be run
The form procedure calls, and thus most pieces of Slope code, take is (procedure-name argument argument argument...) where a procedure name is the first thing in the parenthesis. This is the procedure that is being executed and any values that come after it are arguments to that procedure. Arguments can include calls to other procedures which can have arguments including calls to other procedures and so on forever.
; Here is a nested call to the plus and minus procedures
(+ 5 3 (- 8 7)) ; => 9
In the above example + looks at its arguments and sees that one is not an atom (a single value), but is instead a procedure call. As such, it does that first. So eight minus seven is one. One replaces the call to (- 8 7) and then + runs with its three arguments, producing the result: 9. Note that since we are not doing anything to the nine, like displaying it, you would not see it under normal circumstances. As a convenience the Slope repl will show the result of evaluating the given code, so you would see 9 in the repl.
Procedures have a special form of procedure called lambda to create them. If you wrap a lambda in an extra set of parenthesis that includes the arguments to the lambda (after the lambda's closing parenthesis but inside the extra set) it will call the lambda with the given arguments. This is called an "anonymous procedure". Lambda's can also be stored and referenced as variables via the define procedure (more on that soon). Variadic procedures, procedures that take a variable number of arguments, are possible via the special paramater name ....
Let's create and call an anonymous procedure that adds 2 to a number supplied as an argument to the procedure:
((lambda (x) (+ 2 x))
5)
In the above example we create a procedure that takes one argument. We do this by using the keyword lambda followed by a list of argument names surrounded by parenthesis (this is a special list allowed by the interpreter, see the next section on lists for a more normal usage of lists) followed by the body of the procedure. The last thing evaluated in a procedure is what is returned. So in this case we are giving 5 to the anonymous procedure. The five replaces the x in (+ 2 x) and that returns 7, which is the last thing evaluated in the lambda and is thus returned.
We can update the above to take any number of arguments, add them up, and then add two to them (though it will be more complicated and require some procedures we have not used):
((lambda (...) (apply + (cons 2 ...)))
5 3 1)
In the above the values 5 3 and 1 are given to the lambda. Since it uses the variadic ... special argument all of them get bundled up into a list and given to the anonymous procedure and that list can be referenced by .... The procedure apply is then called with + as an argument and a new procedure call cons with its own arguments of 2 and .... The call to cons adds 2 to the beginning of the list .... Then apply applies that list to +. In this case you can think of it resulting in (+ 2 5 3 1), which returns 11. This is an admittedly in the weeds explanation. If you are just beginning with Slope, ignore this part until you need it. It will make more sense later.
Release 1.2.12 introduced optional type checking at a procedure level. The type checking happens at procedure call time, not during parse. The type checking uses predicate procedures to validate the value being passed to the procedure. You write your procedure in the same way, but any paramater that you want to have a specific type you append an at symbol (@) followed by a procedure name that is available in the calling environment:
(define square (lambda (n@number?) (* n n)))
number? is a predicate that checks if the given value is a number or not and returns a boolean indicating that fact. If the given predicate returns #f a runtime panic will be initiated and listed as a type error in the given procedure (the one being called, not the predicate).
This method of type checking adds a small amount of overhead, but is suitable for general use as needed. It is not the same as static typing in a language like C, Go, Rust, etc. It is most useful during development, or to write cleaner procedures that do not need to have a bunch of boilerplate code to check all of the values coming into them.
Predicate typing does have the benefit that creating a new type is as simple as creating a new predicate. For example, if you created a new data structure called struct and had a procedure that would generate a struct, you would just need to add a struct? procedure (it can be named anything you like) and you can now require a struct by using a paramater like s@struct? in some procedure you want to use to deal with structs. It is a flexible system that can validate arbitrary values by passing a procedure as a part of the paramater name rather than doing a bunch of checks and custom error messages inside the procedure body.
At present it is not possible to provide a custom error message for a type exception that arises from passing a value that does not pass a given predicate. It is also not possible to redirect or control the program flow when an exception of this type is raised. It is a simple mechanism for mission critical typed values: situations where the program must crash and burn if the given value is not right. This mostly comes up during development or when dealing with input from a user. Lastly, this calling convention does not work with the macro special form, only lambda.
All procedure calls are technically lists, which is the main data structure in Slope. A procedure call is a list that includes a keyword representing a procedure and then its arguments. The Slope interpreter is set up to operate on this as the standard case. So to create a list of data, as opposed to a procedure call you can do one of two things.
Use a procedure called, you guessed it, list:
(list 1 2 3 4 5)
Which creates the list (1 2 3 4 5). or use some syntactic sugar:
[1 2 3 4 5]
Both will produce the same list. The square brackets may be easier to see in a wall of code. The lexer for Slope just converts the square brackets into the list procedure call.
Creating variables in Slope is very simple. To create a variable in the current scope you use the define procedure. To change the value of a variable in an accessible scope you use the set! procedure.
(define my-number 55)
(display my-number) ; Prints => 55
(set! my-number 2)
(display my-number) ; Prints => 2Anything can be set as a variable, including the result of a procedure, or a procedure itself:
;; Create a procedure tied to a variable
(define square (lambda (n) (* n n)))
;; Call the procedure
(display (square 5)) ; Prints => 25
;; Set a variable to the result of a procedure
(define is-true? #f)
(define magic-number (if is-true? 10 23))
(display magic-number) ; Prints => 23Variables are scoped to where they are created.
(define x 5)
(define y 2)
(define my-proc (lambda (x)
(define y 100)
(* x y)))
(display (* x y)) ; Prints => 10
(display (my-proc 3)) ; Prints => 300If a variable isn't available in the most local scope, the parent scope will be searched. This will continue all the way up to global scope. If the variable still is not found, an exception will be produced.
define will always define for the current scope. set! will always update the value in the closest scope that it can find the variable. This allows for closures ↗ to work as well.
In most cases you can reference a variable by just using the symbol (name) associated with it. However, modules and user defined namespaces work differently. You must use a special calling convention that includes the name of the namespace. To load a module in Slope you use the load-mod procedure. If you have a module named, for example, json you could load it and use its variable parse like so:
(load-mod json)
(json::parse "my-file.json")
The format is the namespace two colons and the variable within the namespace/module: json::parse. Once you have loaded a module via load-mod any usage information that module exposes can be discovered by using the namespace and the two colons: (usage json::). This will give you a list of variables. You can also just get the usage of one of the variables: (usage json::parse).
You cannot use define or set! with modules. They are immutable once loaded (you can alter their source code manually before loading them, but to the Slope system they are immutable). In addition to modules, there are user defined namespaces. You can create these on the fly, add variables to them, update those variables, and, if you like, export the whole namespace. There will be more information on user defined namespaces later on in this document.
Slope is a dynamically typed language. Values are easily coerced into other types and you do not need to declare what types you are using when creating variables or procedures. However, that does not mean you do not need to pay attention to or know about what types are being used at various points in your programs. There are a wide array of type checking predicate procedures available and it is often wise to make sure your procedures have actually received what they are looking for.
Slope has 9 types: bool, exception, io-handle, list, macro, number, procedure, string, and symbol. An additional three types are available if the gui module is built at interpreter compile time: gui-root, gui-widget, and gui-container. The gui modules are completely optional and cannot be guaranteed on a given system. Check the slope version for the gui label: slope -v to verify presence of gui, or use the exists? procedure to see if a gui procedure is available: (exists? "gui-create").
A string litteral is anything between a set of double-quotes:
"I am a string."
Double quotes can be used inside a string by escaping them with the \ character:
"I am a \"string\"."There are a number of other escape sequences available within strings:
| Sequence Example | Description |
|---|---|
"\a" |
An alert/bell |
"\b" |
A backspace character |
"\f" |
A form feed character |
"\n" |
A newline character |
"\r" |
A carriage return character |
"\v" |
A vertical tab character |
"\\" |
A literal backslash character |
"\"" |
A literal double quote |
"\27" |
A character referenced by its rune number in decimal format |
"\033" |
A character referenced by its rune number in octal format (which uses a leading 0) |
"\0x1B" |
A character referenced by its rune number in hexadecimal format (which uses a leading 0x) |
Raw strings are strings that no escapes are processed for... mostly. To create a raw string you wrap a string in backticks: `I\nam\na\nraw\nstring`. With regular strings wrapped in double quotes that would result in each word being on its own line. But with a raw string what you see is what you get. The one exception to this is that you can escape a backtick like so: `Here is a backtick: \`.`.
You may be thinking, 'if there are no escapes how to I do a newline or a tab?'... you just do it in the source as you want it to appear:
(display `Hello
world...
Hi?`)This is an easy and convenient way to do things like templating or creating help text for your programs and is especially useful when providing patterns for regular expressions.
All numbers in Slope are implemented as 64 bit (or 32 bit on 32 bit systems) floating point numbers under the hood. This can have some odd effects with certain math operations, but is otherwise a convenient way of treating decimal values and whole numbers as a single data type.
A number can be represented three ways (more if you want to use strings and conversion, but that can be a pain and is outside the scope of this writeup):
123 ; decimal, is what you would expect
0xFFF ; hexadecimal, has a leading '0x'
054 ; octal, has a leading '0'
Only the decimal representation allows for fractional values (ex. 23.612).
As mentioned in the section on strings, you can use any of the three formats as an escape value by prepending them with a \ to get the character represented by the given numerical value (rune).
A bool is simple. It is the literal value true, represented by #t in Slope, or false, represented by #f in Slope.
The bool type is really just that simple. Two options. However, many things treat something as being "truthy" or "falsy". In Slope the only falsy value is #f (false) itself. Anything else is considered a truthy value to anything standard construct that cares about truthiness (I'm looking at you if, cond, and case procedures - look them up with usage).
There is one standard library exception to the above: the ~bool procedure. Which takes any value and will return a bool. However, it considers an empty string, an empty list, a closed io-handle, or the number zero, in addition to false itself, to be #f. So if you need a looser rendering of bool, you can always cast a value to bool via the ~bool procedure.
Symbols are tricky things to reason about to beginners. Variable names are symbols, for example. But if you check their type with the type procedure, they will be the type of the value they represent. You can create a symbol using the quote procedure or its syntactic sugar shorthand ':
(quote hello)
'helloBoth of those do the same thing: produce a symbol called hello. You can use symbols in all kinds of places. But if you use them wrong the interpreter may complain that it cannot find a variable named whatever your symbol is. As you use more of the language you will get a feel for when to use symbols (the answer is likely: not too often).
As an aside: the quote procedure or its shorthand can quickly make a list as well: '(1 2 3) is the same as (list 1 2 3) or [1 2 3]. Though that doesn't have much to do with symbols.
An exception is how Slope thinks of errors... things that are not as they should be. Slope offers two exception modes that can be toggled between. The system defaults to doing a runtime panic when an exception is reached (also known as exception-mode-panic), but can be made to pass the exception as a value instead (exception-mode-pass), which can be useful under certain circumstances, or could be used to create the equivalent of a try/except block found in some other languages.
There is no exception literal, but an exception can be created via the ! procedure:
(! "Oh my! Something has gone awry!")There are a number of subtypes for io-handles:
file (read-only)file (write-only)string-bufnet-connnet-conn (tls)
All of these use the same reading and writing procedures (read-all, read-all-bytes, read-all-lines, read-bytes, read-char, read-line, write, write-bytes, write-raw).
With the exception of the optional gui types, io-handles are the only true reference types in Slope. Passing an io-handle to a procedure passes a reference to the io-handle rather than a copy of it. This is a necessity for conveniently working with files, buffers, and network connections.
An io-handle also has a state: closed or open. This can be tested for with the predicate procedure open?. All io-handles should be closed when their usefulness is over. This can be done with the close procedure. The interpreter will attempt to clean up any open files or connections before exiting or panicking.
Lists are the only true built in data structure in Slope. All Slope code that is not just a single atomic value is made up of lists in one form or another. Lists are created either with the list procedure or via syntactic sugar as a "list literal":
(list 1 2 3)
[1 2 3]
Lists are also the basis for associative lists. Associative lists are made up of a list of lists where the inner lists serve as key/value pairs: [["age" 39]["sign" "gemini"]]. The assoc procedure enables this structure to be used similar to a map structure in other languages:
(define my-assoc [["age" 39]["sign" "gemini"]])
(display (assoc my-assoc "age")) ; Prints => 39
(set! my-assoc (assoc my-assoc "age" 40))
(display (assoc my-assoc "age")) ; Prints => 40
There are a fairly large number of procedures in the standard library to manipulate lists and associative lists. Search for them using usage.
Since lists are the only inbuilt data structure in Slope, it makes sense to go over some basic uses. Here are a number of standard operations:
;;Create a list with a bunch of stuff in it
(define my-list [1 "b" 'c [4 5 6] (lambda () (display "Hi"))])
;; Get the first item in a list
(car my-list) ; => 1
;; Get the rest of the list after the first item
(cdr my-list) ; => ("b" c (4 5 6) (lambda () (display "Hi")))
;; Reverse the list
(reverse my-list) ; => ((lambda () (display "Hi") (4 5 6) c "b" a))
;; Call the procedure at the end of `my-list`
((car (reverse my-list))) ; => Prints: Hi!
;; Get a specific item from a list
(ref my-list 1) ; => "b"
;; Set an item from a list
(ref my-list 1 "z") ; => (1 "z" c (4 5 6) (lambda () (display "Hi")))
;; Set an item, but reference the list rather than copy
(ref my-list 1 "z" #t) ; => (1 "z" c (4 5 6) (lambda () (display "Hi")))
;; Get a specific item from a sublist
(ref my-list [3 1]) ; => 5
;; Filter a list
(filter (lambda (item) (number? item)) my-list) ; => (1)
;; Lets's reset our list to a list of numbers
(set! my-list [1 2 3 4])
;; Reduce out list
(reduce + 0 my-list) ; => 10
;; Make our list a string separated by commas
(list->string my-list ", ") ; => "1, 2, 3, 4"
;; Join two lists
(list-join my-list [5 6 7 8]) ; => (1 2 3 4 5 6 7 8)
;; Append to a list
(append my-list 5) ; => (1 2 3 4 5)
(append my-list [5 6 7 8]) ; => (1 2 3 4 (5 6 7 8))
;; Prepend to a list
(cons 0 my-list) ; => (0 1 2 3 4)
;; Create a list for a number range
(range 10 0 2) ; > (0 2 4 6 8 10 12 14 16 18)
;; Seed a list with values
(list-seed 10 #f) ; => (#f #f #f #f #f #f #f #f #f #f)
Procedures are created with the lambda procedure, which is implemented as a special form by the interpreter. Procedures are called by wrapping the procedure name and any arguments as a list:
(my-proc "hi" (+ 1 2))
All arguments to a procedure will be evaluated before being given to the procedure itself. So the second argument, above, will be 3. This is in contrast to macros, which do not evaluate their arguments. Keep reading to see the same example as a macro. What do you think the second argument will be received as?
Macros are created with the macro procedure, which is implemented as a special form by the interpreter. Macros are called just like procedures, by wrapping the macroname and any arguments as a list:
(my-macro "hi" (+ 1 2))
In the above example the first argument my-macro receives will be the string "hi". The second argument will be a list containing the symbol + and the two numbers 1 and 2. If this were a procedure instead of a macro the string would be received and the evaluated result of the + procedure (3 in this case) would have been received.
Arguments passed to macros are not evaluated unless the body of the macro evaluates them (sometimes implicitly, by using them in other procedures, or explicitly via the eval procedure). This allows the manipulation of code, rather than values. With this, you can create new constructs that could not otherwise be created. For example, if could be created as a macro (it isnt, but it could be), since a macro can do partial evaluation, but a procedure cannot. There will be a deeper dive on using and creating macros later in this document.
Slope is able to load arbitrary files with the load procedure. But this requires an absolute path to a given file. That makes it hard to distribute code for others to run.
To improve situations you can use the load-mod procedure. Using load-mod allows you to load a module from a designated location on your system by simply passing the module's name (as represented by the directory name it is contained within). A module can contain any Slope code but only define, load-mod, and load-mod-file calls will be evaluated. Modules have a specific structure that will be gone over later. You may also alias a module by passing a second argument to load-mod that will allow you to reference symbols within a module via that alias.
Modules are loaded into separate namespaces and are thus sandboxed from other code. You cannot use define or set! on a module's symbols. A module author can provide procedures that set module variables though, as a module can modify itself. To reference a symbol within a module you use the module name (or alias), two colons, and then the symbol you want to reference: my-module::some-procedure.
As an example, let's load two modules and alias one of them. Then call a procedure from each:
(load-mod json)
(load-mod cli-forms forms) ; cli-forms gets aliased to 'forms'
(define config
(json::parse
(forms::input "Config file")))
In the aboe example we aliased cli-forms to forms for brevity's sake. So if we wanted to get usage information from that module we would execute (usage forms::), since the alias gets used anywhere the original module name would be used.
Calling load-mod will load the first module(s) it finds that matches the name(s) passed to it. It will search the following locations and use the first non-empty string value as the local search path for modules:
$SLOPE_MOD_PATH$XDG_DATA_HOME/slope/modules~/.local/share/slope/modules
After determining the local path it will look for the module that was requested. If the module does not exist on the local module path it will search the global module path: /usr/local/lib/slope/modules. A local module will always be used over a global module if both exist.
When load-mod is called the module will be located and it's main.slo file will be parsed. All expressions are ignored except calls to define, load-mod, and load-mod-file. This limits but does not at all eliminate the danger of arbitrary code execution. If you define something like the following, there will still be arbitrary code execution: (define a (display "HI!")). The string "HI!" still gets printed. So be careful when you load modules. Know what you are loading and use vetted trusted sources where possible.
Calling load-mod from within a module allows modules to have their own dependencies. Calling load-mod-file allows modules to be made up of more files than just main.slo. More info about files can be found in the next section.
Module's have a minimum of one file to be a valid module: main.slo. It must be in the root level of the module folder.
Taking as an example a module named test, the bare minimum that the folder (or any other valid local folder path ending in the directory test) ~/.local/share/slope/modules/test should contain is a file named main.slo. When a module is loaded, this is the file that is looked for. If it is not present, loading will fail and a runtime panic will result. This file is the entry point to loading the definitions included in the module as well as calling the loading of other files.
You may, optionally, have other code files present in the module and can load them by calling load-mod-file. This procedure should be given a path relative to the module root directory. So within our main.slo file we might call something like: (load-mod-file "./submodules/unit-tests.slo"). Something to note is that a call to load-mod-file cannot jump out of the module's root directory (doing something like (load-mod-file "../../../some-other-code.py") or (load-mod-file "/etc/something") will result in a runtime panic).
Modules found in the package registry will include this file. It contains metadata related to the package including things like description, version, repository url, homepage, author, and most importantly: the dependency list (so that a modules dependencies can also be installed). For details about what this file can/should contain, see the package repository ↗.
Modules should contain a value named _USAGE in their main.slo file. This value should be an association list detailing each procedure/value exposed by the module. It should take the form of:
; This is for a module named: "mymodule"
(define _USAGE [
["my-proc"
"(my-proc [name: string]) => bool\nFurther info can go here. Provide what would be useful"]
["my-other-proc"
"(my-other-proc [name: string] [count: number]) => string"]])
This variable (_USAGE) is special and will be parsed so that the information can be viewed via calls to usage, most commonly at the slope REPL:
; to get a list of values within the given module
(usage mymodule::)
; to get info on a single procedure
(usage mymodule::my-proc)That is a lot of talk about loading modules... but where does one get modules? That is what we will talk about in the next section...
slp ↗ is a separate program from the Slope interpreter. It interacts with a central module repository to allow for installing, removing, searching, and updating modules on your system. It also has a handy mode that will install a module to the correct place on your system. So if you download a module manually from the internet that is not in the package registry you can have slp install it. But first you will need slp on your system...
Note:
Installing slp is purely optional. You can manually manage packages if you want to. If you do not plan to use slp you can skip ahead
Pre-built binaries of slp are not currently available. As such, you will need to build from source. You will need a few things on your system, all of which are also required to build Slope (so you likely have them by now):
To install slp (once all of the above pre-requisites are met), open a terminal emulator run the following:
git clone https://tildegit.org/slope-lang/slp
cd slp
sudo make install
If you do not have administration privileges on your system replace the line sudo make install with make and you can just move the file slp to somewhere on your $PATH.
Now that slp is installed on your system you may want to find some fun modules to use! Let's walk through a few basic slp commands. You can always run slp help at your shell prompt to view slp's help output. Or you can run man slp to view the man page (if you installed via sudo make install or manually moved the file from the repo to your manpath).
You can search slp. Let's look for a csv module. First thing is first; let's update the local registry:
slp fetchYou do not have to do this before every action, but slp may request you do it if it has been awhile since you last did so.
With that done, we can do our search:
slp search csvWhich outputs something like:
searching for "csv"
csv / A module for working csv files
Current version: 0.1.0Now we can install it:
slp install csvWhich outputs something like:
installing csv
├ staging "csv"
├ moving staged items to modules folder
└ done
INSTALLED 1 package (csv)
You can remove installed packages with slp remove my-package-name. To list installed packages run slp installed. To list all packages slp knows about run slp list (good if you just want to browse). To install a module that you have downloaded manually run slp local /path/to/my-module. You can update packages with slp update my-package-name. There are a number of other options as well. Please consult slp help for the full list. This should be enough to get you started though!
If you have installed slp the easiest way to get started creating a module is to run slp gen. That will ask you a series of questions. It will then create a folder with the module name you supplied during the questions. In that folder will be a main.slo file, a module.json file with most of the information filled in, and a README.md file. All of these files will have boilerplate filled in to get you a quick start. The folder will also be initialized as a git repository. From there you can just start coding in the main.slo file, filling out the README.md as things develop.
[~/Documents/slope] $ slp gen
Mandatory fields are marked with an (*).
Non-mandatory fields may be left blank.
Note that fields that are required by the package registry are
not mandatory here simply due to the fact that the information
may not be available when starting a new project.
Remember to go back and update this information.
package title*: my-module
description*: An example module
author*: sloum
version: 0.1.0
repository:
tag: 0.1.0
homepage:
Package "my-module" has been created!You can do all of this by hand, of course:
mkdir my-module
cd my-module
git init
touch main.slo module.json README.mdThe files won't have the boilerplate in them and the json file will be empty. To see what needs to go in the json file you can read the readme in the package repository ↗.
You should always include a variable called _USAGE documenting your module (see above for more info). Only include symbols that you want users to access in the _USAGE association.
If you want your module added to the main package repository you will need to create a pull request in the package repository ↗. We are working on creating a more automated system for this in the future.
This section covers various things that don't fall into the sections above. There will be more actual code examples and less technical detail in prose.
Macros allow for meta programming. Which, for our purposes, means that macros allow you to get at the arguments of a special form of procedure (you guessed it: a macro) without them being evaluated first. Being able to control when evaluation happens allows you to form new constructs that wouldn't be possible using only lambda. For our example we will create a conditional structure called when. If a predicate is truthy all of the code passed to when will be run. If not, then it will not be evaluated.
(define when
(macro (predicate ...)
(eval ['if predicate (cons 'begin ...)])))
As you can see it mostly looks like a procedure. However, we are using eval and we are quoting a number of things and building odd lists...
eval will treat a regular list as code. In other words it will look for nested procedures and arguments. So we pass it a list. In that list we quote out things that we do not want to be evaluated yet. So if gets quoted and passed as a symbol into the list so that list, which is implicitly called when using square brackets, doesn't look up the procedure/special form yet. Only the symbol is put into the list. predicate gets put into the list next. Then we call cons and prepend the symbol begin (not the procedure: note the ' prepending begin) to the rest of the arguments (which are already a list since ... was used).
Now we can use our macro:
(when #f (display 1))
Which will not output 1 since a falsy predicate was given. If this had been created as a lambda then (display 1) would have been evaluated before it even got to the inside of the procedure, since that is how procedures work. With macros, it does not evaluate it first.
Macros can be a really confusing topic at first, and this has likely only helped a small bit to push you in the right direction. It is key to know what to quote and what not to quote in a macro, and takes some trial and error to get the hang of. You can think of all Slope code as lists. So it is natural that a macro would construct a list. The interpreter things of things as lists. For example:
(+ 1 (- 8 3))Is thought of by the interpreter similarly to (the quotes wouldn't actually be there, but are displayed here to make clear that the symbol is in the list, not what it represents):
['+ ['- 8 3]]
It then calls eval internally to evaluate the arguments to each procedure (first item in each nested list) before evaluating the full list itself. So inside a macro, you are striving to construct a list the way the interpreter wants things. Then you can call eval and get the output from your new construct.
All in all when is a pretty simple construct. Lots of new things are possible with macros. A popular one in the lisp/scheme world is let, which allows you to essentially create a block scope and instantiate variables to that block scope. You can find that and a few other macros in the example/macros.slo file within the main Slope interpreter source code repository.
When you load a module it is put into a namespace, which can be thought of as a little area separate from the global namespace. Module symbols are referenced by using the module name (or alias) two colons and the symbol being referenced: (json::parse "my.json"). This serves a few purposes. One of the biggest is that it prevents name collisions such as the standard library having a procedure called, for example, begin... and you wanting to use begin to mean something different in your module/code. With a namespace you can do that: (my-module::begin). But modules are immutable. Wouldn't it be nice to have that separation in your own files? Enter user namespaces.
There are a set of procedures in the standard library that allow you to create and manipulate user namespaces. A big use case for this is prototyping at the Slope repl. Once you have a set of procedures that might make a good module you can move them all into a namespace. Then you can export that namespace and save it to a file for later use! No need to duplicate work by copying and pasting or re-coding into a file. Let's go through an example workflow:
;; Start by creating two simple procedures
(define hello (lambda () (display "Hello")))
(define goodbye (lambda () (display "Goodbye!")))
;; Create a namespace called "print"
(ns-create 'print)
;; Add our two procedures to the namespace
(ns-define 'print 'hello hello)
(ns-define 'print 'goodbye goodbye)
;; Let's verify what is in our namespace
(display (ns-list 'print)) ; Prints => ("hello" "goodbye")
;; Let's say we don't want goodby after all
(ns-delete 'print 'goodbye)
;; Let's verify what is in our namespace
(display (ns-list 'print)) ; Prints => ("hello")
;; Now we will update 'hello in our namespace
(ns-define 'print 'hello (lambda () (display "Hello, world!")))
;; We can call things from our namespace
(print::hello) ; Prints => Hello, world!
;; Let's create a file
;; write our namespace to it
;; and close the file
;; throwing an exception if the file could not
;; be opened for writing
(define f (file-open-write "./print.slo"))
(if f
(close
(write
(ns->string 'print)
f))
(! "Could not open file for writing"))
That is clearly a very simplified example, but it should give you a basic idea of how to work with user namespaces. If you are curious as to what the file has in it now, let's use cat at the shell prompt and take a look:
[~/Documents/code/slope] $ cat print.slo
;;; print
;; Exported via ns->string:
(define hello (lambda () (display "Hello, world!")))
We could change the name of the file to main.slo and put it in a folder called print. We could then run slp local ./print and install our module locally (slp could not update it since it does not have a remote source, but it can list it or remove it now that it is installed). Then we could easily include it in other projects via (load-mod print).
Syntax files/plugins are available for a number of editors:
Assuming you have compiled in the GUI module you can start developing basic GUI applications. Slope's GUI module allows for fairly straightforward form style graphical applications. It does not support free drawing or other more complicated cases, but is great for interfacing with files or apis.
In this walkthrough we will create a "Hello, world!" graphical application. Note that the main Slope source code repository has a file, examples/gui-test.slo, that showcases a number of widgets, keybindings, and other features. This runthrough is intended to get you up and running with the basics.
The GUI module includes three new types:
gui-rootgui-containergui-widget
A gui-root is created by the procedure gui-create. There can only be one per application. Once you have a gui-root you will need to add at least one window to it. That window will need at least one gui-container in it and one gui-widget in the container (you can, of course, always have more of any of these).
;; Create a gui-root and a label widget
(define app (gui-create))
(define label (widget-make-label "Hello, world!"))
;; Add a window to our gui-root
;; Name the window "main"
(gui-add-window app "main")
;; Set the content of the window "main"
;; to a max layout container that contains
;; the label we created
(window-set-content app "main" (container "max" label))
;; Set the window title (optional)
(window-set-title app "main" "Hello, world (example)")
;; Run the application
(window-show-and-run app "main")And we get this:
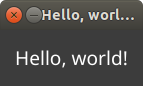
In theory we did not really need a lasting reference to the label widget in this case and could have passed the procedure result directly to container. In actual code it will be of benefit to maintain a reference to various widgets/containers and is generally good practice to keep them around to reference in callbacks and other such situations.
The gui module contains procedures to allow images, rendered markdown, form fields, callbacks on said fields, file browsing, and more. As well as enough layouts to make fairly complex applications. Under the hood Slope uses the fyne toolkit ↗, which is a native golang gui toolkit that will look the same on each os, allowing quick, easy, and consistent graphical applications.
When working with Slope as an interactive coding tool, usually via the repl, it can be nice to have certain niceties loaded up for you each time. Procedures that you regularly use, but are not a part of a module. This can be accomplished by preloading.
The Slope interpreter allows for files in a specific directory to be automatically loaded. For this to occur slope should be invoked with the -L flag: slope -L. This works running as a repl, with files, or with -run. When that flag is passed the interpreter will do its normal setup routine then preload all files in the preload folder then go on to executing your repl session, file, or -run script.
Unlike modules, arbitrary code execution can occur with preloads (not just define expressions). The rationalle is that you, the user, have put this code there. As such it is considered safe and in your control. Preloads are a really easy way to make procedures and variables outside of the standard library, but that you regularly use, available to you without having to manually load them. Additionally, you may call load or load-mod from within preloaded files to further expand the working environment on load.
The directory will be searched for and the first valid folder it finds will be used. The list of search paths is as follows:
$SLOPE_PRELOAD_DIR$XDG_DATA_HOME/slope/preload/~/.local/share/slope/preload/Using an io-handle is necessary when working with outside environemnts (networks, file systems, etc). Here we will cover some basic usage patterns.
Let's start with reading:
;; Open the file for reading
(define my-file (file-open-read "./example.txt"))
;; Check if the file is open and perform an action
;; Return an exception otherwise (which will panic)
(if my-file
(display (read-all my-file))
(! "Couldn't read my-file"))
; Prints => Hello, world!
;; Close the file when done with it
(close my-file)It works the same way with a network connection, so let's try writing to one:
;; Open a network connection
(define my-conn (net-conn "colorfield.space" 70))
;; Throw an exception if we couldn't connect
(if (not my-conn) (! "Could not open net-conn my-conn"))
;; Write to the connection, read, display the result
(display (read-all (write "/\r\n" my-conn)))
;; Truncated result:
;; i` , * . . ` , * . false null.host 1
;; i ` , ` , * . . . ; ` false null.host 1
;; i . ` * . c f | s . ` * . false null.host 1
;; i` * . . o i | p ` * . . false null.host 1
;; i . ` , . l e | a . ` * . false null.host 1
;; i` ; . . o l | c * . . false null.host 1
;; i . ` * . r d | e . ` . ` false null.host 1
;; i - - - - - - - - - - - - _ _ _ _ _ - - - - - - - - - - - - false null.host 1
(close my-conn)
This example reads a gopher ↗ site/hole. A net-conn io-handle can be read from or written to without having to re-open (files are in either read or write mode). Since write returns the io-handle that it was passed, we can then pass that directly to read-all as a nested call. We could also have done this as a separate line, but the read surrounding write is an established pattern that is useful in Slope.
Writing to a file works just the same, but passing the result of write to read-all does not work as expected since the file is open in read mode (via file-open-read). To open a file in write mode use file-open-write. If you just need to append text to the end of a file you can use: (file-append-to "my-file-path.txt" "My text to append") and avoid using an io-handle at all.
Something else to remember is that since an io-handle is a reference to an open file, connection, or buffer they can easily be passed around between procedures. No copy is made.
Coming soon...
In this section all of the procedures in the standard library, including the optional gui module, are listed and described. A search form is provided in order to search both the procedure names and their descriptions to help find the desired procedure.
(+ [number...]) ; => numberAdds the given numbers together, left to right, and returns the sum. If only one number is provided it is simply returned.
(- [number...]) ; => numberSubtracts the given numbers from each other, left to right, and returns the result. If only one number is provided its sign is inversed and it is returned.
(* [number...]) ; => numberMultiplies the given numbers and returns the result, If only one number is provided then 1 is divided by it and the result is returned.
(/ [number...]) ; => numberDivides the given numbers, left to right, and returns the result. If only one number is provided it is simply returned.
(% [number] [number]) ; => numberReturns the modulus of the two given numbers. If an invalid pair of numbers is given, the result will be zero (since slope does not contain an undefined or NaN value). This has the potential to cause problems, be aware.
(| [number] [number]) ; => numberReturns the bitwise or of two numbers.
(& [number] [number]) ; => numberReturns the bitwise and of two numbers.
(^ [number] [[number]]) ; => numberReturns the bitwise xor of two numbers, or the bitwise not of a single number.
(<< [number] [number]) ; => numberBit shifts the first number left by the second number.
(>> [number] [[number]]) ; => numberBit shifts the first number right by the second number.
(> [number] [number]) ; => boolChecks of the first number is greater than the second number.
(>= [number] [number]) ; => boolChecks if the first number is greater than or equal to the second number.
(< [number] [number]) ; => boolChecks if the first number is less than the second number.
(<= [number] [number]) ; => boolChecks if the first number is less than or equal to the second number.
(~bool [value]) ; => bool
~bool will convert a given value to a boolean value using a looser set of rules than if would normally use: 0, 0.0, (), "", and a closed io-handle will be considered falsy (in addition to #f).
(! [exception-text: string]) ; => exceptionReturn an error with the given text. Depending on the error mode this may result in a runtime panic or simply in the exception value being passed to the calling lambda.
(abs [number]) ; => numberReturns the absolute value of a given number.
(and [expression...]) ; => bool
Checks the truthiness of all expressions passed to it. If any expression is falsy then false is returned and no further expressions are checked; otherwise returns #t.
(append [list|value] [[value...]]) ; => list|stringIf a list is the only argument, it will be returned. If a list is followed by other values they will be appended to the list and the list will be returned. If a single non-list value is given it will be coerced to string and returned. If multiple non-list values are given they will be coerced to string and concatenated with the resulting string being returned.
(apply [procedure] [arguments: list]) ; => valueSpreads the list values as arguments to the given procedure. This results in behavior where the following two examples are equivalent:
(+ 1 2 3) ; => 6
(apply + [1 2 3]) ; => 6(assoc [association-list] [key: value] [[value]]) ; => value|list
If two arguments are given then assoc retrieves the value of the key. If a third argument is given assoc will set the value for the given key to the given value, returning the updated list.
(assoc? [value]) ; => bool
Determines whether or not the given value is an association list. An empty list will return #t, as an empty association is no different than an empty list.
(atan [number] [[number]]) ; => numberReturns the atan value of a given number. If two numbers are given returns the atan2 value of the given numbers.
(atom? [value]) ; => boolDetermines whether a given value is atomic (in practice this mostly works out to: not a list).
(begin [expression...]) ; => valueEvaluates a series of expressions and returns the value of the last expression that is evaluated.
(begin [expression...]) ; => valueEvaluates a series of expressions and returns the value of the first expression that is evaluated.
(bool? [value]) ; => bool
Checks whether the given value is a boolean: either the value #t or the value #f.
(byte? [value]) ; => boolChecks whether the given value is a byte, a number between from 0 to 255
(bytes->string [number|list]) ; => stringIf a single number is given, a string of the given value will be returned. If a list is given, that list should only contain bytes (numbers from 0-255). The list of numbers will be treated as a list of bytes and will be converted to a string.
(car [list]) ; => value|listReturns the first value in the given list, which may be an atomic value or another list.
(case [target-match: value] [([match-value: expression] [#t-branch: expression])...]) ; => valueWill check if each the given target-value matches each match-value in turn and evaluate to the #t-branch of the first such match that is equal. If no match is found an empty list will be returned. The match-value `else` is a sepcial case, the #t-branch of this match list will be returned if no other match is found to be truthy.
(cdr [list]) ; => list
Returns the given list without its first value. Can be thought of as the remainder of car.
(ceil [number]) ; => numberReturn the ceiling value of the given number.
(ceil 1.23) ; => 2
(ceil 1) ; => 1(chdir [filepath: string]) ; => ()Changes the current working directory to the given filepath. Will return an exception if it was unable to change to the given filepath.
(chmod [filepath: string] [file-mode: number]) ; => ()Changes the filepermissions for the given file to the given file-mode number. Will return an exception if it was not possible to apply the given file-mode to the given filepath. The file-mode can be any format of number (octal, decimal, hex) so long as it represents a valid file-mode for the operating system.
(close [io-handle]) ; => ()Closes the given io-handle. Can be called on an already closed io-handle without an exception. Will return an exception if an open io-handle cannot be closed.
(coeval [expression...]) ; => ()Concurrently evaluates each expression given to coeval. `coeval` will block until all expressions have finished evaluation, but the individual expressions will be evaluated concurrently. This is mostly useful for side effects such as writing to many files at once or dealing with many network connections while maintaining understandable and obvious control flow in the program.
(cond [([condition: expression] [#t-branch: expression])...]) ; => value
Will evaluate each condition in turn and evaluate to the #t-branch of the first condition that is truthy. If no condition is truthy then an empty list will be returned. The value else is a sepcial case allowed as the final condition expression, the #t-branch of this condition list will be returned if no other condition is found to be truthy.
(cons [value] [list]) ; => listPrepends the given value to the given list, and returns the list. See also: append, which can add an item to the end of a list.
(container [layout: string] [[columns: number]] [contents: gui-widget|container...])
container is the basic layout unit of the slope gui system. It can hold any number of other widgets or containers. The columns value is shown as optional, despite having a mandatory value after it, because it is only available for the grid layout. Do not pass columns for any other layout. The available layout strings are:
nonehboxvboxformgridmaxpaddedborder#f for one of these values(container-add-to [parent: gui-container] [child: gui-widget|gui-container]) => #tAdds the given child widget/container to the given parent container.
(container-scroll [gui-container]) => gui-container
Takes a single, unlike the other containers, container (which can in turn contain widgets or other containers). The minimum size of the container it is passed will be ignored and scroll bars will be added as needed. Note that since container-scroll does not accept more than one gui-container a call to container-add-to targeting a container generated by container-scroll will result in a runtime panic.
(container-size [gui-container]) => list
Returns a two item list containing the given gui-container's width and height (in that order).
(cos [number]) ; => numberReturns the cos value of a given number.
(date [[format: string]]) ; => stringReturns the current date/time, optionally formatted by a format string argument.
(date-format [start-format: string] [date: string] [end-format: string]) ; => stringConverts a date rendered in the format given by start-format to a date rendered in the format given by end-format and returns that date string.
Date format/pattern substitutions:
%apm%APM%d4%D04%e 4%fJan%FJanuary%g or %G15%h2%H02%i4%I04%m6%M06%o-07%O-0700%s5%S05%wWed%WWednesday%y21%Y2021%ZUTC, PST, etc.%%%Anything else?, as will a hanging % as the last char in the string
So the string: "F %e, %Y %h:%I%a would be equivalend to something like: August 8, 2021 4:03pm
When a string is converted to a date and no time zone information is present, slope will assume the user's local time.
(date->timestamp [date: string] [date-format: string]) ; => numberConverts a date string that matches the given date-format to a unix timestamp.
Date format/pattern substitutions:
%apm%APM%d4%D04%e 4%fJan%FJanuary%g or %G15%h2%H02%i4%I04%m6%M06%o-07%O-0700%s5%S05%wWed%WWednesday%y21%Y2021%ZUTC, PST, etc.%%%Anything else?, as will a hanging % as the last char in the string
So the string: "F %e, %Y %h:%I%a would be equivalend to something like: August 8, 2021 4:03pm
When a string is converted to a date and no time zone information is present, slope will assume the user's local time.
(date-default-format) ; => stringReturns a format string for the default format produced by date.
(define [var-name: symbol] [value|expression|procedure]) ; => value|expression|procedure
Returns the value that var-name was set to, in addition to creating the var symbol in the current scope and setting it to the given value. define is lexically scoped (using define within a lambda will create a variable that is only visible to that lambda and its child scopes, but not to any parent scopes). var-name should be a symbol that represents the name of the new variable.
devnull ; => io-handle (file: write-only)
io-handle for devnull. This value is mutable, so you may redefine it, but it is recommended to store the original value elsewhere if you find the need to redefine it.
(dialog-error [gui-root] [window-name: string] [error: string]) => ()Shows an error message. The dialog that is opened is not a system native dialog and will be constrained by the window size.
(dialog-info [gui-root] [window-name: string] [title: string] [message: string]) => ()Shows an information window with the given title and message. The dialog that is opened is not a system native dialog and will be constrained by the window size.
(dialog-open-file [app: gui-root] [window-name: string] [callback: lambda]) => ()Creates an open file dialog. The given lambda should take one argument, a string representing the selected file path. The dialog that is opened is not a system native dialog and will be constrained by the window size.
(dialog-save-file [app: gui-root] [window-name: string] [callback: lambda]) => ()Creates an save file dialog. The given lambda should take one argument, a string representing the selected file path. The dialog that is opened is not a system native dialog and will be constrained by the window size.
(display [value...]) ; => ()
Print the given values to stdout. Similar to: (write "..."), but can take multiple arguments and can only write to stdout. Display will stringify (make into a string) any value it is given before printing it.
(display-lines [value...]) ; => ()
Prints the given values to stdout while adding a terminating newline to each value.
E ; => number
This value is case sensitive and represents the numerical constant (representation here is truncated for display): 2.7182818284590452353602874713.
(env [[env-key: string]] [[env-value: string]]) ; => association-list|string|()When passed with no arguments will return an association list of the current environment variables. When passed with an env-key, will return an env-value as a string, or an empty string if the key could not be found. If passed an env-key and an env-value env will set the given key to the given value in the current env and return an empty list.
For example:
(env "SHELL") ; => /bin/bash
(env "SHELL" "/bin/tcsh"); => ()
(env "SHELL") ; => /bin/tcsh(equal? [value...]) ; => bool
Checks if the given values are equal. If only one value is given iequal? will return #t.
(eval [expression|value] [[treat-string-as-code: bool]]) ; => value
Eval will exaluate the given value/expression. If treat-string-as-code is set to #t a string representation of slope code passed as a value will be evaluated as code. Otherwise, a string would evaluate to itself (a string).
(exception? [value: any]) ; => boolChecks if the given value is an exception.
(exception-mode-panic) ; => ()Sets the exception mode such that if an exception is encountered a runtime panic will be triggered. This is the slope default behavior.
(exception-mode-pass) ; => ()Sets the exception mode such that if an exception is encountered it is returned to the calling scope as a value.
(exception-mode-panic?) ; => bool
Checks if the current exception mode is panic.
(exception-mode-pass?) ; => bool
Determines whether the current exception mode is pass.
(exists? [quoted-symbol...]) ; => bool
Determines whether the given symbol(s) exist in the current environment. If multiple values are passed #t will only be returned if all of the symbols are present. All symbols given to exists? should be quoted: (exists? '+) ; => #t. Strings representing symbols may also be passed: (exists? "+") ; => #t.
(exit [[exit-code: number]]) ; => ()Causes the program to exit with an exit code of 0. If an optional exit-code is given it will be used instead of the default, 0.
(file-append-to [filepath: string] [string...]) ; => ()
Appends the given strings to the given file. If the file does not exist, it is created. Appending to the file is an atomic opperation and should not lock the file. A file is not opened and thus there is no need to call close. An empty list is returned.
(file-create [filepath: string]) ; => io-handleCreates a file at the given filepath. If a file already exists, the file is truncated. Returns an open io-handle representing the file.
(file-create-temp [filename-pattern: string]) ; => io-handle
Creates a temporary file in the system default location for temporary files. The filename is generated by taking the filename-pattern and adding a random string to the end. If the filename-pattern includes a * the random string replaces the last *. Returns an open io-handle representing the file. To get the file name see: file-name.
(file-name [io-handle]) ; => stringReturns a string representing the full path of the file associated with the given io-handle.
(file-open-read [filepath: string]) ; => io-handleReturns an open io-handle for the file represented by the given filepath. The file is opened in read mode.
(file-open-write [filepath: string]) ; => io-handleReturns an open io-handle for the file represented by the given filepath. The file is opened in write mode.
(file-stat [filepath: string]) ; => assoc-list|#fGets information about the file represented by filepath. The returned associative list will have the following keys:
name (string)size (bytes: number)mode (number)mod-time (number)is-dir? (bool)is-symlink? (bool)path (string)owner (string)group (string)modestring (string)
#f will be returned if the file does not exist; all other file access errors will raise an exception. mode will default to decimal formatting, as all numbers do in slope, but it can be cast to an octal string with number->string. path will be an absolute path after following a symlink, if present, or the path as provided to stat in the absense of a symlink.
(filter [test: procedure] [list]) ; => listThe procedure supplied to filter should take one value, the list item being passed to it, and will have its return value treated as a bool. Any value in the list that returns truthy when fed to the test procedure will be included in the list that filter returns.
(floor [number]) ; => numberReturns the floor value of the given number. For example:
(floor 2.78) ; => 2
(floor 2) ; => 2
(floor 2.123455) ; => 2(for ([([symbol] [value] [update: expression])]...) ([test: expression] [return: value|expression]) [body: expression...]) => value
for is a general purpose looping construct. Since slope does not offer tail recursion elimination it is the safest and most performant way to do extended looping for which the stack would overflow if recursion was used. for is general purpose and can be used to create other looping structures via macro or lambda. Example usage that prints the numbers 1-5:
(for ((x 1 (+ x 1))) ((not (equal? x 6)) x)
(display x))
; Prints: 12345
; Returns => 6(for-each [procedure] [list...]) ; => ()
Works via the same rules as map, but is used specifically for side effects rather than return values. Will run the procedure for each list item in each list, if more than one list is passed. For example, if the procedure takes two arguments and two lists were given the procedure will be called with the first item in the first list as its first argument and the first item in the second list as its second argument. It will then procede to the second item in each list as arguments, and so on.
(gui-add-shortcut [gui-root] [window-name: string] [callback: lambda] [key: string] [modifier: string]) => #tAdds a shortcut to the window. Any time the two given keys are pressed the lambda will be called with no arguments. The valid modifiers are:
altctrl, control, ctl, strgshift, shsuper, sup, windows, win, command, com
The available key strings are given in CamelCase with the first character always capitalized. Some examples are: F1, Left, Down, Tab, Q, 4, BackSpace, Home. Note that single characters are always uppercase for purposes of providing a key to this procedure.
(gui-add-window [app: gui-root] [name: string])
Adds a window to the given gui-root as returned by gui-create. Name will be used to refer to the newly created window in other procedures. A string is prefered and called for in the procedure signature, but any other value can be used and will be stringified.
(gui-create) => gui-root
Creates the application root for a gui application. See: gui-add-window for information about adding content to a gui-root. In general you will always want to use define when creating a gui-root as everything is done by passing it as a reference later on in the development process for GUI applications.
(gui-list-windows [app: gui-root]) => list
Returns a list containing the name of each window associated with the given gui-root.
(gui-set-char-handlers [gui-root] [window-name: string] [callback: lambda]) => #t
Sets up all single key keypress handlers for the given window. This is distinct from shortcuts, which are made by a key chord (Ctrl/Shift/Alt/Mod+Something). The lambda should accept a string, which will always be a single character representing the character that was input. All kepresses that are not used by a widget (for example, an entry widget accepts text and will not further pass on the keypresses) will have the callback called with the character that was input as the input to the procedure. Note that it is the character and not the key. As such k and K are different. The character based nature also means that non-printable items (arrows, enter, backspace, etc) are not caught by this procedure. It is suggested that you use an if or cond statement inside of the lambda to sort them into the effects you want to achieve for any given character.
(gui-use-light-theme [[bool]]) => bool
If no arguments are given gui-use-light-theme will check is a light theme is being used and return #t if so, #f if not. Any value passed to gui-use-light-theme will be coerced to a bool. If the given value is #t then the gui will be set to use the light them, otherwise the dark theme will be used.
(hostname) ; => stringReturns the host name reported by the kernel as a string.
(if [condition: expression] [#t-branch: expression] [[#f-branch: expression]]) ; => value
The expression given to if as its condition will be evaluated and its value will be taken as truthy or falsy. Any value other than #f is considered truthy for the purposes of the condition. If the condition evaluates to a truthy value then the #t-branch will be evaluated, otherwise it will be ignore and the #f-branch will be evaluated if one was given.
(inspect [[name: string]]) => bool
Runs a subrepl at the given place in the code in which inspect was evaluated, allowing access the the environment at runtime. Any changes to the environment will persist once inspect is returns. inspect is intended to be used for debugging and having live access to an environment within a scope. To leave the inspect procedure you must call uninspect as the only thing called on a given line at the repl. So: (uninspect). inspect will return #t if it was able to function. The only time it will return #f (and have no other effect) is if the given program is not attached to a tty, such as when the program is called as part of a shell pipeline. uninspect is a special word recognized by the subrepl and is not a true procedure, thus it does not have its own usage information.
If a name is provided it will be used as the prompt for the subrepl. This allows for calling inspect from within a subrepl; it allows you to know which repl you are in.
(io-handle? [value]) ; => boolChecks if the given value is an io-handle.
(lambda [([[argument: symbol...]])] [expression...]) ; => procedure
Lambda is how you make reusable code (functions, procedures, etc) in slope. The special values args-list or ... can be given as an argument name. If this argument name is used it will always be a list and will contain any number of arguments given starting at its position in the argument list. There is an implicit (ie. created for you) begin block that will surround expression.... As such you do not need to add your own. lambda creates its own scope and any define statements within the lambda will be scoped to the lambda (available to it and any child scopes), thus creating a closure. Examples:
((lambda (num1 num2)
(display num1 "+" num2)
(+ num1 num2)) 5 7)
; Prints: 5+7
; => 12
((lambda ()
(display "Hi!")))
; Prints: Hi!
((lambda (sys-args)
(apply * sys-args)) [2 3 4])
; => 24(length [list|string|exception|io-handle_string-buf]) ; => numberReturns the length of the given value. Length is determined by number of code points (runes) for strings and number of items for lists. Exceptions and io-handles for string buffers are converted to their string value for purposes of getting their length.
(license) ; => ()Prints the slope interpreter's software license (for the interpreter itself, not for slope code run with the interpreter).
(list [value...]) ; => listReturns a list containing the given values. Syntactic sugar exists to make list creation shorter:
;; This:
(list 1 2 3)
;; Is equal to this:
[1 2 3]
;; Is equal to this:
'(1 2 3)(list? [value]) ; => boolChecks whether the given value is a list, empty or filled.
(list->string [list] [[join-on: string]]) ; => stringConverts the given list to a string, inserting the optional join-on string between each list item. Any non-string items in the list will be converted to strings automatically before joining.
(list-seed [length: number] [value]) ; => list
Using list seed to create lists filled with a certain element is more efficient than recursion for large lists and will not overflow the stack. As such list-seed will return a lift of the given length filled with the given value at each index. length should be a positive number larger than zero. If a floating point number is given, it will be floored.
(list-sort [list] [[sub-list-index: number]]) ; => list
Sorts a list alphabetically first followed by numerals. Any non-number non-string value will be sorted by its stringified value. If list is a list of lists, sorting can be done by the index value of a sublist (a single level deep) if desired. list-sort always sorts the list in ascending order, but can be reversed with reverse.
(load [filepath: string...]) ; => symbol
load will open the file represented by filepath and evaluate its contents as slope code. It will run any code within the file. load can accept a relative reference, which will be treated as relative to the current working directory. Any define statements within the laoded file will result in the symbol getting added to the global environment. As such it is recommended to avoid scope confusion by always calling load from your code's top level scope. Unlike load-mod, load will evaluate all code within the file, not solely calls define, so be sure you really want to load the given file and know what it does. load is variadic and can accept any number of filepaths as strings. They will be loaded one after the other, left to right.
(load-mod [module-name: string|symbol] [alias: string|symbol]) ; => symbol
load-mod will search the local module path followed by the gloval module path for the given module. If found, locally or globally, the file main.slo within the module folder will be parsed. Arbitrary code will not be executed, only define, load-mod, and load-mod-file statements will be evaluated. This prevents some level of arbitrary code execution, but it is still possible to embed malicious code in lambda expressions that get defined. Be sure you know what a module does or that it is from a trusted source. The code is available for each module on the system for you to look at and you are encouraged to do so. Modules loaded via load-mod can have their symbols referenced in the following manner: module-name::module-symbol. For example, a hypothetical JSON module might have the following procedure: json::parse. Or maybe it was loaded with the alias 'j': (load-mod json j) which would allow it to call the same procedure as j::parse.
(load-mod-file [filepath: string]) ; => symbol
load-mod-file is used within modules to do a relative load of files that are a part of the module, but are not main.slo. The same evaluation rules as load-mod apply to load-mod-file (only define, load-mod, and load-mod-file calls will be evaluated). A quirk of load-mod-file is that it can be used outside of modules similar to load, but with the given load restrictions. So if you want to load the definitions in a module and not evaluate globally scoped non-definition code load-mod-file can accomplish that.
(log [number]) ; => numberReturns the natural log value of a given number.
(macro [([[argument: symbol...]])] [expression...]) ; => macro
Macro is how you extend the control structures of slope. The special value ... can be given as an argument name. If this argument name is used it will always be a list and will contain any number of arguments given starting at its position in the argument list. There is an implicit (ie. created for you) begin block that will surround expression.... As such you do not need to add your own. macro creates its own scope and any define statements within the macro will be scoped to the macro (available to it and any child scopes). The difference between lambda and macro is that arguments to lambda are evaluated and arguments to macro are not. As such, code is manipulated rather than value, or a mix of the two occurs. This enables behaviors not possible with lambda. Example:
(define let
(macro (args ...)
(define in (map (lambda (inargs) (car inargs)) args))
(define out (map (lambda (outargs) (eval (car (cdr outargs)))) args))
(define l (eval ['lambda in (cons 'begin ...)]) )
(apply l out)))
(let ((a 12)(b (+ 5 3))) (+ a b)) ; => 20
(+ a b) ; => Exception, symbols a and b do not exist(macro? [value]) ; => boolChecks if the given value is a macro.
(map [procedure] [list...]) ; => list
map will pass the values of each list as arguments to the given prcedure and a new list will be created from the results. If multiple lists are given, they should be the same length and their values will be given as arguments such that the first argument of each list will be provided to the given procedure (as two arguments in the case of two lists, three in the case of three etc), then the second argument, and so on.
(max [number...]) ; => numberReturns the largest of the given numbers.
(member? [list] [value]) ; => boolChecks whether the given value is in the given list.
(min [number...]) ; => numberReturns the smallest of the given numbers.
(mkdir [path: string] [permissions: number] [[make-all: bool]]) ; => ()Creates the directory at the given path. Permissions for the directory must be given, usually as an octal number (but any numerical representation that is valid is fine). If the optional argument make-all is #t any parent directories in the given path that do not exist will also be created with the given file permissions.
(mod-path) ; => string
Returns the current module path. The module path is calculated each time mod-path is called in order to detect changes. As such, this is more expensive than a runtime constant.
(mv [from-path: string] [to-path: string]) ; => ()
Moves the file represented by from-path to to-path.
(negative? [number]) ; => boolChecks if the given number is less than zero.
(net-conn [host: string] [port: string|number] [[use-tls: bool]] [[timeout-seconds: number]]) ; => io-handle|#f
Returns an open io-handle or #f if the connection failed or timed out (an exception if the arguments were not valid). The returned io-handle represents a TCP connection to the given host at the given port. If the optional value use-tls is set to #t then TLS will be used. If the optional value timeout-seconds is set to a positive number #f will be returned and the connection will time out if the connection does not occur within the given number of seconds. If timeout-seconds is not given or is less than 1 there is no timeout and an invalid connection attempt will hang indefinitely. In general it is a good idea to use a timeout for most use cases.
(net-get [url: string]) => list
Accepts http(s), gopher, and gemini url schemes. net-get will request the resource found at the given url and return a list where the first item is a bool indicating that the request was successful or not. The second item in the list is either the response body or the error message (if the first value is #f). Gemini requests will also have a third item in the list indicating the mime type of a successful request or an empty string for a failed request.
(net-listen [network: string|symbol] [addres:: string|symbol] [callback: proc|macro] [[init-callback: proc|macro]]) => ()
Listens for incoming requests at the given address, which should generally include a port (ex: 127.0.0.1:3000). network should be one of the following:
tcp (which will accept IPv4 or IPv6)tcp4tcp6unixunixsocket
Any other network will result in an error. The network value is not case sensitive.
callback should accept one argument: an io-handle. net-listen automatically does an infinite loop to listen for requests, when one is received the callback will be called in its own coroutine, passing the connection as an argument to the callback (as an open io-handle). It is the callback's responsibility to close the io-handle it is given.
The optional argument init-callback will be called once, before the infinite loop starts; it should accept two arguments: the network and the address, both as strings. The init callback is useful for printing information to the screen or doing any needed setup. The most common usage is to display that net-listen is active and what network type, host, and port it is using.
If there is an error accepting a connection the error will be returned, ending the infinite loop. Otherwise, net-listen will go on forever and the caller will have to use Ctrl+c to exit the program.
(net-post [url: string] [data: io-handle|string] [[mime: string]]) => list
Accepts http(s), gopher, and gemini url schemes. net-post will request the resource found at the given url and return a list where the first item is a bool indicating that the request was successful or not. The second item in the list is either the response body or the error message (if the first value is #f). Gemini requests will also have a third item in the list indicating the mime type of a successful request or an empty string for a failed request.
In addition to making the request to the url the request body will include the data found in the io-handle or string. In the case of http(s) this will be passed as post data. In the case of gemini or gopher this is just a shorthand for adding the data to the url as a query paramater. When making an http(s) post request via net-post the mime type will default to text/plain unless an alternate mime type is provided. Providing a mim type for gemini or gopher requests has no additional effect.
(newline) ; => ()
Prints a newline character to stdout.
(not [value]) ; => bool
not will invert the truthiness of the value it is given such that a truthy falue returns #f and #f returns #t.
(ns->string [ns-name: string|symbol]) => string
Returns a formatted and stringified version of the given namespace, as represented by ns-name, suitable for dumping to a file for later use via load or, with a little bit of effort setting up a few other module items, load-mod.
Note that to reference other symbols within the namespace you must use the namespace calling convention (namespace::symbol). ns->string will automatically adjust the references so that its output will use the local global scope and allow the code to be loaded normally (ie. namespace references will be removed).
(ns-create [ns-name: string|symbol]) => true
Creates an empty namespace with the given ns-name. The ns-name cannot contain an ascii space character, colon, apostrophe, open paren, closing paren, quote, or hash character as these are reserved for use elswhere in the slope system. Once values are defined within the namespace (via ns-define) they can by called the same as you would call code from a loaded module using the namespace::symbol syntax.
Note that to reference other symbols within the namespace you must use the namespace calling convention (namespace::symbol). ns->string will automatically adjust the references so that its output will use the local global scope and allow the code to be loaded normally (ie. namespace references will be removed).
(ns-define [ns-name: string|symbol] [identifier: string|symbol] [value: any]) => any
Adds the given identifier and value to the given namespace, as represented by ns-name and returns the value. There is no set! equivalent and ns-define can be used to update the value of a given identifier for a given namespace.
Note that to reference other symbols within the namespace you must use the namespace calling convention (namespace::symbol). ns->string will automatically adjust the references so that its output will use the local global scope and allow the code to be loaded normally (ie. namespace references will be removed).
(ns-delete [ns-name: string|symbol] [[identifier: string|symbol]]) => true
If an identifier is given that identifier and its associated value will be removed from the given namespace, as represented by ns-name. If no identifier is given, the given namespace, as represented by ns-name, will itself be removed from the system.
(ns-list [[ns-name: string|symbol]]) => list
If no namespace is given ns-list will return a list of the namespaces that have been created by ns-create within the current slope session. This list will not include modules loaded via load-mod. If a namespace, as represented by ns-name, is given then a list of the identifiers within that namespace will be returned.
(number? [value]) ; => boolChecks if the given value is a number.
(number->string [number] [[base: number]]) ; => string
The value for base defaults to 10 (decimal). If a value other than 10 is provided then the number will be parsed as an integer and output in the given base. If the value for base is 10 or is not given, the number will be parsed as a floating point number. All other bases will be parsed as integers.
(null? [value]) ; => boolChecks if the given value is an empty list.
(open? [io-handle]) ; => boolChecks whether or not the given io-handle is currently open.
(or [expression...]) ; => bool
Evaluates each expression in turn. If any expression evaluates to a truthy value #t is returned and no further arguments are evaluated, otherwise #f is returned.
PHI ; => number
This value is case sensitive and represents the numerical constant (representation here is truncated for display): 1.6180339887498948482045868343;.
PI ; => number
This value is case sensitive and represents the numerical constant (representation here is truncated for display): 3.1415926535897932384626433832;.
(pair? [value]) ; => boolChecks if the given value is a non-empty list.
(path-abs [filepath: string]) ; => string
Creates an absolute path from the given filepath by resolving all relative references and expanding ~.
(path-base [filepath: string]) ; => stringReturns the last element in the given filepath, removing a trailing slash if one is present.
(path-base "/home/someuser/.vimrc") ; => ".vimrc"
(path-base "/home/someuser/.vim/") ; => ".vim"(path-dir [filepath: string]) ; => stringReturns all of the path minus the element after the last path separator, removing a trailing path separator from the result (if one is present).
(path-dir "/home/someuser/.vim") ; => "/home/someuser"
(path-dir "/home/someuser/.vim/") ; => "/home/someuser/.vim"(path-exists? [filepath: string]) ; => boolCheckes whether the given filepath exists.
(path-extension [filepath: string] [[replacement-extension: string]]) ; => string
Returns the file extension for the file the given filepath points to, as defined as everything from the last ., i.e. .txt. If there is no extension an empty string is returned. If a replacement-extension is given it will replace the original extension and the full path, including the new extension, will be returned. The replacement-extension should include a . if it is wanted in the new path as the prior . will be removed as part of the replacement procedure.
(path-glob [filepath: string]) ; => list
Returns a list of filepaths that match the glob pattern provided as filepath. A glob is created by inserting a * character. For example:
(path-glob "/home/*/.bashrc") ; => ["/home/someone/.bashrc" "/home/otherperson/.bashrc"]
(path-glob "/home/myuser/.*") ; => ["/home/myuser/.bashrc" "/home/myuser/.profile" "/home/myuser/.vimrc"](path-is-dir? [filepath: string]) ; => boolChecks whether or not the given filepath represents a directory
(path-join [[path-segment: string...]]) ; => stringJoins the given path-segments by the path separator appropriate for the given system. If no path-segments are passed the root direcotry is returned.
(positive? [number]) ; => boolChecks if the given number is greater than zero
(procedure? [value]) ; => boolChecks if the given value is a procedure (a lambda).
(pwd) ; => stringReturns the current working directory as a string.
(quote [expression...]) ; => bool
(rand [[max]] [[min]]) ; => number
If no arguments are given rand will produce a floating point number between 0 and 1. If only max is given, rand will produce a floating point number between 0 and max. If max and min are both given, rand will produce a floating point number between min and max. max is always exclusive (the value produced will always be less than max), while min is inclusize. To obtain integers use floor, ceil, or round on the result or rand
(range [[count: number]] [[start: number]] [[step: number]]) ; => list
If no arguments are given an empty list will be returned. count should be a positive integer
and represents the number of list items that will be produced by range. If no arguments other
than count are given then a list from 0 to count will be produced. To start at a number other
than zero start can be given. To step by a value other than one, step can be given.
(range) ; => ()
(range 5) ; => (0 1 2 3 4)
(range 5 10) ; => (10 11 12 13 14)
(range 5 10 2) ; => (10 12 14 16 18)(read-all [[io-handle]]) ; => string
Reads all data the io-handle has available (either a whole file, whole buffer, until ^D is sent to stdin, or until a net connection is closed) and returns the content as a string.
(read-all-bytes [[io-handle]]) ; => listReads all content from the given io-handle (defaulting to stdin) and returns it as a list of numbers representing bytes.
(read-all-lines [[io-handle]]) ; => list
Reads all data the io-handle has available (either a whole file, whole buffer, until ^D is sent to stdin, or until a net connection is closed) and splits it into a list of lines, split on \n.
(read-bytes [[io-handle]] [[count: number]]) ; => list|number|#f
Reads count bytes from the given io-handle and returns them as a list of numbers. If count is not given, it will default to 1. count must be a positive number larger than 0. If count is 1, the byte will be returned as a number, not a list of numbers. If no io-handle is given, stdin will be used. Does not opperate on string buffers. If the io-handle cannot be read from #f will be returned.
(read-char [[io-handle]]) ; => string|#f
Reads a single character from the given io-handle. If no io-handle is provided then stdin will be used. read-char cannot read a character from a string buffer. If there is no more to be read (eother the end of the file has been reached or the connection has been closed) #f will be returned.
(read-line [[io-handle]]) ; => string|#f
Reads a line from the given io-handle (with the exception of a string buffer, which does not support partial reads) and returns it as a string. If there is no more to be read (either the end of the file has been reached or the connection has been closed) #f will be returned. If no io-handle is passed stdin will be used and will read until a newline is encountered.
(reduce [procedure] [accumulator: value] [list]); => list
reduce will pass the values of each list item and the current accumulator value as arguments to the given prcedure and will return the state of the accumulator after all list items have been given, in order, to the procedure. The procedure should return the accumulator value that will be given, along with the next list item, to the procedure. Thus, the accumulator will change over the course of running reduce and its initial state is just a starting point.
(ref [list|string] [index: list|number] [[set: value]] [[relative?: bool]]) ; => value|list|string
Gets or sets an item in a given list|string by its index position. Indexing begins at 0. When the optional set argument is provided the list|string will be returned with the value at the given index replaced by the set value that was given. If a string is being operated on and an empty string is given as the set value the index will be removed. If a list is given along with an index, set value, and relative? is #t, the value will be updated in place without need to store the list again with `set!`. `relative?` does not affect strings.
To access sublists a list of indexes can be passed.
Negative indexes can be used. The last item in the list/string is index -1.
(ref [1 2 3 4] 2) ; => 3
(ref [[1 2][3 4]] [1 1]); => 4
(ref [1 2 3 4] -2) ; => 3
(ref [1 2 3 4] 2 54) ; => [1 3 54 4]
(ref "Hello" 2) ; => "l"
(ref "Hello" 2 "y") ; => "Heylo"
(ref "Hello" 2 "yyy") ; => "Heyyylo"
(ref "Hello" 2 5) ; => "He5lo"
(ref "Hello" 2 "") ; => "Helo"(regex-find [pattern: string] [string]) ; => listReturns list of all matches to the given regex pattern found in the given string. Slope uses golang's regular expression format.
(regex-match? [pattern: string] [string]) ; => boolChecks if the regex pattern is found at least once in the given string. Slope uses golang's regular expression format.
(regex-replace [pattern: string] [input: string] [replacement: string]) ; => stringReplaces all instances of the given pattern in the given input string with the replacement string. Slope uses golang's regular expression format.
(repl-flush) ; => #tForces a write to the repl history file, truncating the file, and writing the contents of the repl sesssion to the file.
(reverse [list|string]) ; => list|string
reverse will reverse a list or a string and return the same type of value it was given, but with the contents in the reverse order.
(rm [path: string] [[rm-all: bool]]) ; => ()
Removes the file pointed to by path from the filesystem. If rm-all is set to #t all children of the path will be removed as well (a recursive removal).
(round [number] [[decimals-to-round-to: number]]) ; => numberRounds the given number to the nearest whole number. If decimals-to-round-to is provided round will round to that number of decimal places
(rune->bytes [number]) ; => listWill convert the given number representing a rune to a list of numbers representing bytes. Runes in the ascii set will result in a list containing a single number representing a byte, larger runes will usually result in a list containing multiple numbers representing bytes.
(rune->string [number]) ; => stringWill floor any value passed to it and attempt to convert it to a single character string represented by the given number.
(set! [var-name: symbol] [value|expression|procedure]) ; => value | expression | procedure
Returns the value that var-name was set to, in addition to updating the variable represented by var-name to the given value. Only an existing variable can be set with set!, trying to set a non-existant variable will result in an exception. set! will always set the value for the variable in the nearest scope.
(signal-catch-sigint [procedure]) ; => boolThe procedure passed to signal-catch-sigint should take no arguments and will be run upon sigint being received. This will override all default behavior: if you still want the program to exit you will need to call (exit) from within the procedure. This procedure (signal-catch-sigint) should be called at the root level of your program as it will only have access to the global environment.
(sin [number]) ; => numberReturns the sin value of a given number.
(sleep [[milliseconds: number]]) ; => ()Halt further program execution until the given number of milliseconds has passed.
(slice [list|string] [start-index: number] [[end-index: number]]) ; => list|string
slice is used to get a subsection of an indexed item (string or list). end-index is exclusive (should be one higher than the last character you want included in the slice). If end-index is not given then the slice will go from the start position until the end of the list|string. If a start-index larger than the largest available index is given an empty list|string will be returned.
(slope-version [[major: number]] [[minor: number]] [[patch: number]]) ; => list|#t
If given no arguments slope-verseion will return a list with three numbers in it representing the major, minor, and patch versions of the currently running slope runtime. If between one and three numbers are given they will represent the major, minor, and patch version being checked for. If at least one argument is given, but not three, any optional arguments that are not given will default to 0. When arguments are given a check will be done to see if the currently running slope runtime is >= the given values. If it is #t is returned. If it is not, an exception is returned detailing the version needed and the version available. This allows to easily have a version requirement within software, or (with no arguments) to provide alternate behavior paths for varying versions.
Note: This procedure itself was added in version 1.1.0, and will not be available for older runtimes. It will mostly apply moving forward and will take time to become a normal way of operating.
(sqrt [number]) ; => numberReturns the sqrt value of a given number.
stderr ; => io-handle (file: write-only)
io-handle for stderr. This value is mutable, so you may redefine it, but it is recommended to store the original value elsewhere if you find the need to redefine it.
stdin ; => io-handle(file: read-only)
io-handle for stdin. This value is mutable, so you may redefine it, but it is recommended to store the original value elsewhere if you find the need to redefine it.
stdout ; => io-handle (file: write-only)io-handle for stdout
(string? [value]) ; => boolChecks whether the given value is a string.
(string->bytes [string]) ; => listTakes any value and converts it to string (if it is not already a string), then converts that string to a list of numbers representing bytes.
(string->list [string] [[split-on: value]] [[count: number]]) ; => list
Splits the string at each instance of split-on. If split-on is not a string it will be cast to string for the purposes of splitting the string into a list. If a count is provided the string will be split into no more than _count_ list elements.
(string->md5 [string]) ; => stringProduces an md5 hash string from the given string.
(string->rune [string]) ; => rune
Converts the first character in the given string to a rune number. Any other characters in the string will be ignored. If the string is empty string->rune will return 0. The resulting number can be converted back to a string with rune->string.
(string->sha256 [string]) ; => stringProduces a sha256 hash string from the given string.
(string->number [string] [[base: number]]) ; => number/#fIf a non-decimal base is supplied, the input string will be parsed as an integer and any flaoting point value will be floored. A valid base passed with a string that does not parse to a number will return #f
(string-buf? [value]) ; => bool
Checks whether the given value is an io-handle of type string buffer.
(string-buf-clear [io-handle: string-buf]) ; => ()Resets/clears the content from the given string buffer io-handle, resulting in the buffer being empty.
(string-fields [string]) ; => listSplits a string around each instance of one or more consecutive white space characters.
(string-format [template: string] [value...]) ; => string
Replaces values designated by %v in the template string with successive values (value...).
Width can be set by adding an integer between the % and the v: %10v, or left aligned: %-10v
(string-index-of [string] [search-value: string]) ; => number
Returns -1 if search-value does not appear in string, otherwise returns the string index at which search-value begins.
(string-lower [string]) ; => stringConverts all characters in the given string to their lowercase form and returns the new lowercase string.
(string-make-buf) ; => io-handle: string-bufReturns a new empty string buffer io-handle.
(string-replace [source: string] [replace: string] [with: string] [[count: number]]) ; => string
Does a straight string replacement count number of times, defaulting to all matches found. For more complex/flexible matching/replacement use regex-replace.
(string-trim-space [string]) ; => string
Removes any leading or trailing white-space from string.
(string-upper [string]) ; => stringConverts all characters in the given string to their uppercase form and returns the new uppercase string.
(subprocess [list] [[output-redirection: io-handle|#f]] [[error-redirection: io-handle|#f]] [[input-redirection: io-handle|#f]]) ; => number
subprocess takes a list representing a command line argument. THe first item in the list should be the program to execute and all following items should be arguments to that program. Passing #f to any of the redirections causes them to use the std version of said redirection (stdout, stderr, or stdin).
(symbol? [value]) ; => boolChecks if the given value is a symbol.
sys-args ; => list
sys-args is the list of arguments that were invoked to run the currently running slope program. The first argument in the list is always the name of the program that was invoked, which will not include the slope interpreter itself (if invoked directly it will be removed from the list). The list is defined at runtime and is mutable if you set! it, so be careful... be weird if that is your thing. Either way.
(tan [number]) ; => numberReturns the tan value of a given number.
(term-char-mode) ; => ()Changes the terminal to char mode.
(term-cooked-mode) ; => ()Changes the terminal to cooked mode.
(term-raw-mode) ; => ()Changes the terminal to raw mode.
(term-restore) ; => ()Restores the terminal to how it was before any mode changes were instituted.
(term-sane-mode) ; => ()Changes the terminal to sane mode.
(term-size) ; => listReturns a list containing two numbers that represent the width and height of the terminal.
(timestamp) ; => numberReturns a number representing the current date/time in the unix timestamp format.
(timestamp->date [timestamp: string|number] [[format: string]]) ; => stringConverts a timestamp string to a date string that matches the given date-format.
Date format/pattern substitutions:
%apm%APM%d4%D04%e 4%fJan%FJanuary%g or %G15%h2%H02%i4%I04%m6%M06%o-07%O-0700%s5%S05%wWed%WWednesday%y21%Y2021%ZUTC, PST, etc.%%%Anything else?, as will a hanging % as the last char in the string
So the string: "F %e, %Y %h:%I%a would be equivalend to something like: August 8, 2021 4:03pm
When a string is converted to a date and no time zone information is present, slope will assume the user's local time.
(type [value: any]) ; => stringReturns a string describing the type of anything passed to it.
(url-host [url: string] [[new-host: string]]) ; => stringReturns a string representing the host value of the given url. If a new-host value is provided the whole url will be returned but with the original host replaced by the new-host value.
(url-path [url: string] [[new-path: string]]) ; => stringReturns a string representing the path portion of the given url, or an empty string if no path is present. If a new-path value is provided the whole url will be returned but with the original path replaced by the new-path value.
(url-port [url: string] [[new-port: string]]) ; => stringReturns a string representing the port portion of the given url, or an empty string if no port is present. If a new-port value is proviuded the whole url will be returned but with the original port replaced by the new-port value.
(url-query [url: string] [[new-query: string]]) ; => stringReturns a string representing the query portion of the url, or an empty string if no query segment is present. If a new-query value is provided the whole url will be returned but with the original query segment replaced by the new-query value.
(url-scheme [url: string] [[new-scheme: string]]) ; => stringReturns a string representing the scheme portion of the url. If a new-scheme value is provided the whole url will be returned but with the original scheme replaced by the new-scheme value.
(usage [[module-or-built-in-name: string|symbol]]) ; => ()
If not passed a value, usage will display a list of all known built-in procedures as well a list of loaded modules and any aliases they may have. When given a value equal to a built-in procedure a description of that value will be output to stdout. When passed the name of a loaded module, including the colons (my-module::), a list of symbols that the module supplies usage information for will be printed to stdout. When passed the name of a module symbol reference (my-module::some-symbol) the usage information will be printed to stdout. Any time any unknown/unavailable information is requested a notice of that fact will be printed to stdout.
(widget-add-to-size [gui-widget] [width-change: number] [height-change: number]) => gui-widget
Updates the width and height of the given widget by adding the width-change value to the current width and the height-change value to the current height. Returns the updated widget.
(widget-disable [gui-widget] [[set-disabled: bool]]) => bool
When called with only a valid gui-widget the current disabled state will be returned (#t means it is disabled). When called with the optional bool set-disabled the widget will be disabled if #t is given and will be enabled if #f is given. Any gui-widget passed to widget-disable that cannot be disabled will return #f for a call to either form of the procedure.
(widget-get-text [gui-widget]) => stringRetrieves the text of the given widget.
(widget-hide [gui-widget]) => #t
Hides the given gui-widget. Calling on an already hidden widget will have no effect.
(widget-make-button [text: string] [callback: lambda] [[alignment: number]] [[importance: number]]) => gui-widgetCreates a button widget with the given text. The callback should accept no arguments and should only create side effects (the return value will be discarded). If alignment is given it should be one of:
-101
If importance is given the buttons styling will change between three modes: least important (importance < 1), highly important (importance > 1), or the default: medium importance (importance = 1).
(widget-make-checkbox [text: string] [callback: lambda]) => gui-widgetCreates a checkbox widget with the given text. The callback should accept one argument representing the boolean state of the checkbox and should only create side effects (the return value will be discarded).
(widget-make-entry [placeholder-text: string] [[wrap-text: bool]] [[validation-callback: lambda]]) => gui-widget
Creates an entry widget with the given placeholder value. For accessibility purposes it is always advised to also have a label widget describing this widget. If a validation lambda is given it should take a string value as its argument and should validate based on that string. If it successfully validates #t should be returned, otherwise a string explaining the error should be returned.
(widget-make-hyperlink [text: string] [url: string]) => gui-widgetCreates a hyperlink widget with the given text linking to the given URL. If the URL cannot be parsed as a valid URL an exception will be returned.
(widget-make-image [source: string] [location: string] [[mode: string]] [[min-width: number]] [[min-height: number]]) => gui-widget
Creates an image widget from the given source. Available sources are: path and url, the later of which will actually load any available URI. The location string represents the address or path of the image. The optional mode argument defaults to fit which will keep the original aspect ratio of the image but size it to fit the container (latching to the smallest container dimension). original may be passed to over-ride the default behavior and use the original image size, expanding the container if need be. Passing a min-width or min-height will cause the resulting image widget to size to this dimension as a minimum value. The way the size minimums work may be surprising as they interact with attempts to keep the aspect ratio and size to the container, so a 50x10 image set to 10x100 will not work, since aspect ratio is being kept. One value will be chosen as the one to use in sizing, this may depend on the type of container.
(widget-make-label [text: string] [[alignment: number]] [[wrap-text: bool]]) => gui-widgetCreates a label widget with the given text. If alignment is given it should be one of:
-101(widget-make-markdown [markdown-text: string] [[wrap-text: bool]]) => gui-widget
Creates a markdown text block. The markdown-text string should be markdown, which will be parsed and rendered. wrap-text defaults to #f. If set to #t the text will be wrapped at word boundaries using the minimum size of the container.
(widget-make-multiline [placeholder-text: string] [[wrap-text: bool]] [[validation-callback: lambda]]) => gui-widget
Creates a multiline text entry widget with the given placeholder value. For accessibility purposes it is always advised to also have a label widget describing this widget. If a validation lambda is given it should take a string value as its argument and should validate based on that string. If it successfully validates #t should be returned, otherwise a string explaining the error should be returned.
(widget-make-password [placeholder-text: string] [[wrap-text: bool]] [[validation-callback: lambda]]) => gui-widget
Creates an password widget with the given placeholder value. For accessibility purposes it is always advised to also have a label widget describing this widget. If a validation lambda is given it should take a string value as its argument and should validate based on that string. If it successfully validates #t should be returned, otherwise a string explaining the error should be returned.
(widget-make-select [options: list] [callback: lambda] [[alignment: number]]) => gui-widgetCreates a select widget with the given options. Any non-string options will be converted to string. The callback should accept a string argument representing the selected element and should only create side effects (the return value will be discarded). If alignment is given it should be one of:
-101(widget-make-separator) => gui-widgetReturns a separator widget, which takes the form of a separator line that will go horizontal or vertical automatically depending on the container/layout.
(widget-make-spacer) => gui-widgetReturns a spacer widget which will fill up the available space in the container, pushing other widgets away from it in a direction decided based on the container/layou.
(widget-set-text [gui-widget] [string]) => stringSets the text of the given widget to the given string and returns the string.
(widget-resize [gui-widget] [width: number] [height: number]) => gui-widget
In general the size of widgets is defined by the container/layout. However, in cases where it is not, widget-resize can be used. If used in a situation where it cannot be used, there will be no effect. Returns the widget with the new size.
(widget-show [gui-widget]) => #tShows the given gui-widget. The widget will only become visible if it is in a visible grouping (window, container, layout, etc). Calling on an already visible widget will have no effect.
(widget-size [gui-widget]) => listReturns the given widget's current width and height, in that order, in a two item list.
(window-allow-resize [app: gui-root] [window-name: string] [bool]) => #tSets whether or not to allow the user to resize the given window.
(window-center [app: gui-root] [window-name: string]) => #tCenters the given window on the screen.
(window-close [app: gui-root] [window-name: string]) => #tCloses the given window. When called on an already closed window the behavior is undefined.
(window-hide [app: gui-root] [window-name: string]) => #tHides the given window. There is no effect when called on an already hidden window.
(window-resize [app: gui-root] [window-name: string] [width: number] [height: number]) => #tResizes the given app's given window to the width and height that were given, if possible.
(window-set-content [app: gui-root] [window-name: string] [content: gui-widget|gui-container]) => #t
Sets the content for the given window. This is usually a container, but could be a widget. #t or an exception will be returned.
(window-set-fullscreen [app: gui-root] [window-name: string] [set-to-full-screen: bool]) => #t
Sets the given window to full screen if #t is given and removes it from full screen if #f is given.
(window-set-title [app: gui-root] [window-name: string] [title: string]) => #t
Sets the title of the window to the given title string. If a non-string value is passed as title a stringified version of the value will be used.
(window-show [app: gui-root] [window-name: string]) => #tShows the given window. There is no effect when called on an already visible window.
(window-show-and-run [app: gui-root] [window-name: string]) => #tRuns the gui with the given window visible. This is the main procedure for starting the gui and will block once evaluated until the window is closed.
(write [string] [[io-handle]]) ; => ()|io-handleWrites the given string to stdout. If an optional io-handle has been provided the string will be written to the given io-handle. If the io-handle is closed an exception will occur. Returns an empty list if no io-handle is given, or returns the io-handle if one was given
(write-bytes [bytes: list|number] [[io-handle]]) ; => ()|io-handleWrites the given list of numbers (or a single byte number) to stdout as bytes. If an optional io-handle has been provided the list (or single byte number) will be written to the given io-handle. If the io-handle is closed an exception will occur. Returns an empty list if no io-handle is given, or returns the io-handle if one was given.
(write-raw [string] [[io-handle]]) ; => ()|io-handleWrites the given string to stdout, or an optionally provided io-handle. Does not process any escape values or special characters within the given string. Returns an empty list if no io-handle is given, or returns the given io-handle
(zero? [number]) ; => boolChecks if the given number is zero.